又到了年末的回故,今年發生了好多事情,有好的有壞的,來順著時間線回顧今年發生的事情好了!
四月
今年四月公司舉辦了年度的回訓,細節的過程現在其實已經沒有那麼清晰的記憶了,不過印象中當時主持的組長人很Nice,而且蠻可惜的,最後我的積分沒有得到獎品的書。
說到書,今年看到一本不錯的書,叫做Data Science From Scratch,有提到很多統計、資料清洗之類的,英文的原文書的內容也不會艱澀到看不懂,非常不錯。
這個月還結束了我在台大的工作,非常謝謝窗口的劉先生、王小姐,在我剛起步光環境都架不起來也還是對我相當包容。
這幾個月從非常生疏到熟練有很大成就感跟自我實現的感覺,雖然至此之後沒有機會再使用到ASP.net或是C#,但是MSSQL倒是也被融入到畢業專題裡頭去使用了。
五月
這個月好像沒有什麼特的事情,大概只有在系上做大學推甄的志工?想到幾年前我也是這樣一關一關面試進來的,時間過的真快!
六月
這個月可就刺激了,前半個月沒什麼特別的,就是一如既往的上課、考試,到了月中之後暑假開始,嘉文老師團隊的暑訓也就開始了,從這個月開始我才正式開始做我的畢業專題,我負責把合作廠商的React.Js+Go(好像是Gin)的網站修改成React.Js+Python(Flask)的架構,必重新開發了新的Android App來在Temi機器人上執行,我印象很深,我大概花了兩個禮拜,在六月底時才搞定整個前後端,但是後端還沒有連線器人的能力,因為七月還有別的事情可能會耽誤到專題發的時程,所以我當時相當擔心進度會不夠快。
七月
這個月初接任了公司開的APCS的暑期營隊,帶了兩個梯次的同學進行APCS考試的練習跟觀念的講解,印象中我好像發過一篇心得,我印象比較深刻的是第一次接任全講述類型的班,所以在時間的掌控上沒有拿捏得很好,在後續的幾次好像有慢慢進步的感覺?未來希望還有機會可以再次接任相關的課程或營隊。
後半個月回歸團隊繼續進行開發,這次在WebSocket, Socket, SocketIO之間糾纏了很久,很多文獻說WebSocket跟SocketIO可以互通,但我嘗試了好幾次好像都不太行。
更麻煩的是Flask好像只提供SocketIO,但在Android/Java中好像更容易實現WebSocket,所以又經歷了一番折騰,最後找到一個方法可以讓Flask中的Flask_Socket套件進行WebSocket的連線跟使用,未來有機會再分享如何做到。
八月
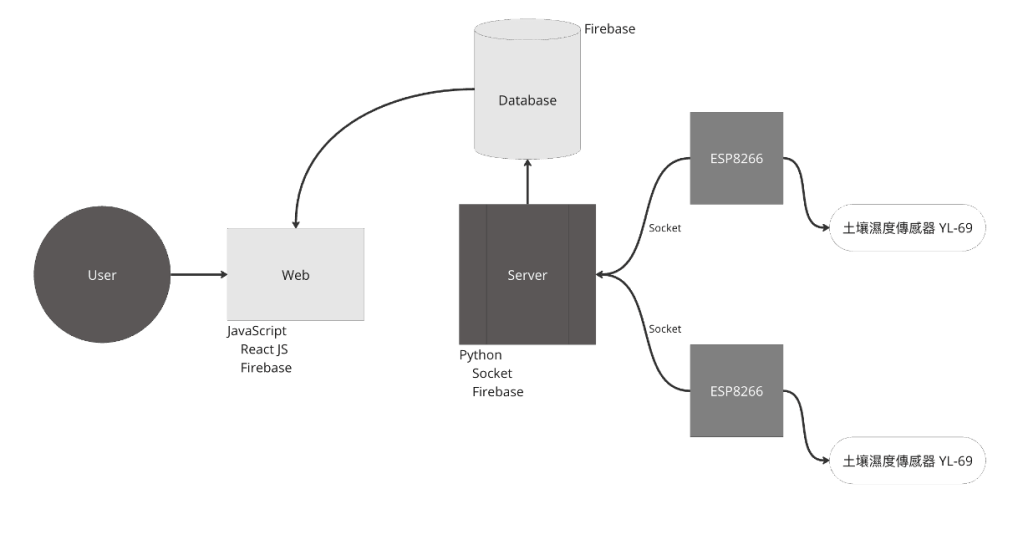
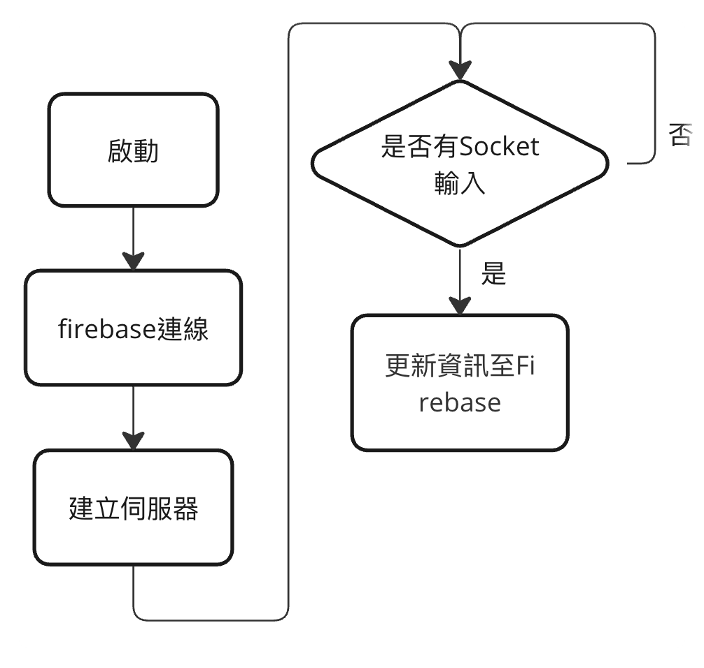
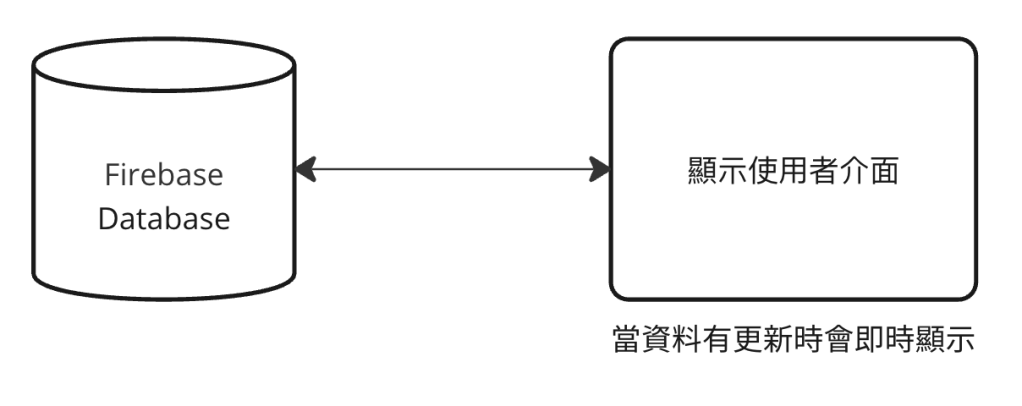
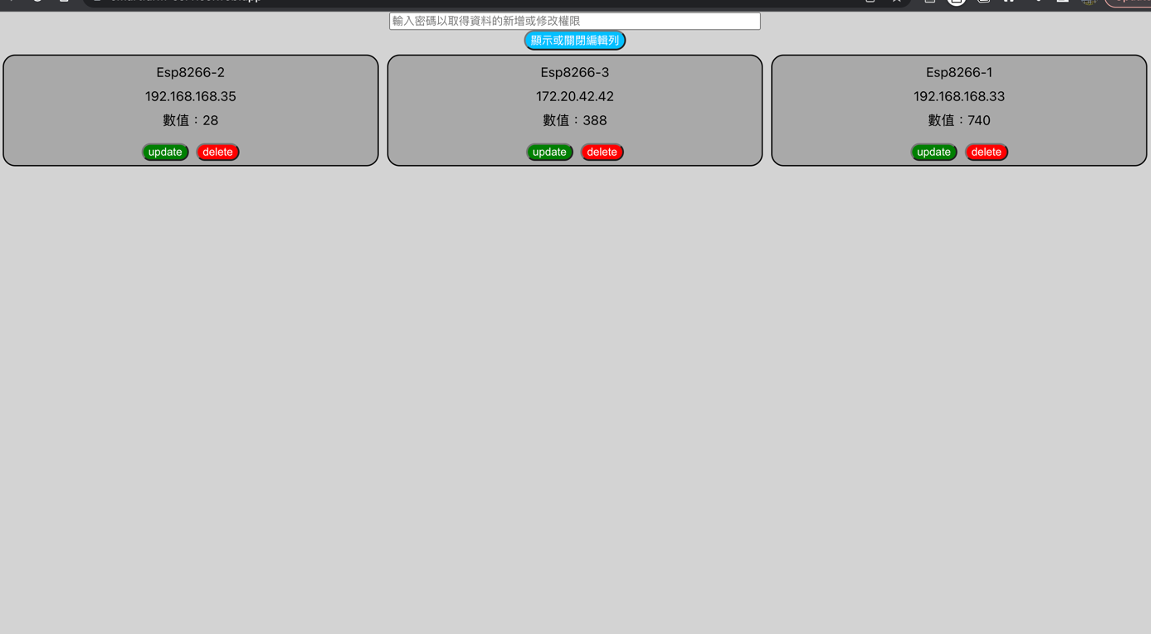
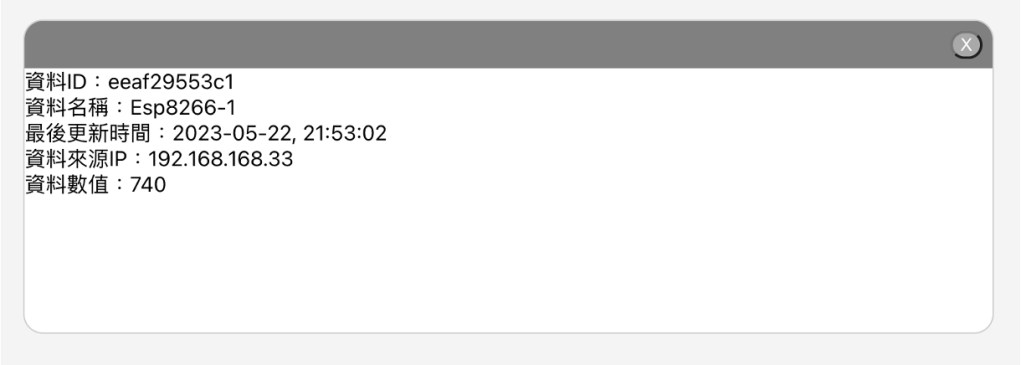
這個月好像就也是一直在做研究跟專題中度過,這個月還負責了團隊中的教學工作,製作了使用ESP8266的教材,跟團對成員分享這段時間做後端跟終端設備(手機、機器人、ESP8266等有連網功能的開發版)互動的一些研究成果。
九月
這個月好像是鐵人賽的樣子,我以研究MOJO為主題報名了,不過最後沒有開賽就結束了,好像是媽媽住院的樣子導致我最後只有寫了兩篇文就沒空再寫了,後來也一直沒有機會補起來,現在發現好像這個話題也慢慢淡掉了,似乎沒有再看到相關的文獻了,不過當時發現了官方部落格的post裡頭有一個很奇怪的比較,官方所說比C快多少倍各位可以當作參考就好。
十月/十一月
這兩個月都忙著在研究所的推甄,準備文件、準備面試口試其實都比想像中的還要費時,也好像可以看到這幾年自己的成長軌跡。
雖然最後放榜時我一直以為自己有意所學校應該會是正取,但可惜所有學校都是備取。
十二月
這個月看到自己的備取名額遲遲未下,所以又報名了明年研究所的考試,也因為專題參加完學校資訊展,算是告一個段落了,所以多了一些空閒時間。
為了不要浪費這些多出來的時間,我決定報名幾個實習的職缺,希望可以縮小一些產學的落差,不知道最後會不會上。
歐對,我還去考了多益,上次考的時候是高中畢業的暑假,兩次都是沒有讀書進去裸考,這次出來不知道是考題變簡單還是我的英文進步很多,感覺好像蠻簡單的,希望不要只是感覺。
總結
好啦,好像也就這樣,今年總體來說有好多新的經驗,學到很多新的酷酷的東西,像是現在正在自學的Django之類的,希望未來一年可以保持一樣的學習熱忱,不管是工作、學習都可以順順利利。