
前言
這邊可能看起來有點像寶可夢宅,不想看可以先跳過~
最近又開始繼續玩寶可夢朱紫了,過去在劍盾時期很認真在打寶可夢雙打,練了不少當時應該算蠻厲害的寶可夢,但很可惜像是堅果啞鈴、鋁鋼龍這些我過去的好虎辦們都沒有申請到簽證沒辦法繼續到朱紫跟我一起奮鬥。
因為我練努力值的方式都是帶護腕之類的道具去農野生寶可夢(藥劑我覺得太貴了),所以我一隻寶可夢通常都需要快20分鐘才能練完。
農怪的同時我也在想說有沒有除了當今的meta之外可以使用寶可夢?也想多看看有沒有具有高種族值的冷門寶可夢可以玩玩看,所以就萌生了這個專案:希望可以透過爬蟲建立一隻系統幫我針對HP、攻擊、特攻、防禦、特防、速度去進行排序或依照種族值、屬性去挑選適合或有潛力的寶可夢去看看。
整體來說,這是一個很好的機會可以讓我去結合興趣跟專長,來做個寶可夢資料爬蟲並使用這些資料去進行一個排序系統吧!
沒意外的話這個專案會持續一段時間,所以有興趣的朋友可以幫我多留意一下新文章的更新並follow我的IG之類的媒體,後續也會將專案Source Code更新到我的GitHub中!
環境
目前因為還在很初期的規劃跟測試,所以是先在Google Colab的環境下進行開發。
唯一需要另外安裝的是opencc-python-reimplemented,可以透過!pip install opencc-python-reimplemented來進行安裝。
opencc-python-reimplemented是一個做繁體、簡體轉換的一個套件,因為這次爬取的網站是神奇宝贝百科,網站中會有一些的簡體字,在閱讀上我個人比較不習慣,所以才採用的,如果你對簡體字閱讀完全沒有問題的話也可以不用沒關係!在程式碼中稍做修正即可。
資料型態
在現階段我只想先取得所有寶可夢的全國編號、世代、中文名稱、英文名稱,所以先來做一個簡單的類別(Class),這個類別只要負責儲存剛剛提到的幾項資料跟顯示出來即可。
from opencc import OpenCC
class Pokemon:
def __init__(self,id,gen,name_zh,name_eng):
cc = OpenCC('s2t')
self.id=id
self.gen=gen
self.name_zh=cc.convert(name_zh)
self.name_eng=name_eng
def show(self):
print(f"ID:\t\t #{str(self.id).zfill(4)}")
print(f"Generation:\t {self.gen}")
print(f"Name_Zh:\t {(self.name_zh)}")
print(f"Name_Eng:\t {self.name_eng}")
print()
完成這個Class之後可以透過以下程式碼來簡單測試一下:
test_data=[
{'id':1,'name_zh': '妙蛙种子', 'name_eng': 'Bulbasaur'},
{'id':2,'name_zh': '妙蛙草', 'name_eng': 'Ivysaur'},
{'id':3,'name_zh': '妙蛙花', 'name_eng': 'Venusaur'},
{'id':4,'name_zh': '小火龙', 'name_eng': 'Charmander'},
{'id':5,'name_zh': '火恐龙', 'name_eng': 'Charmeleon'},
{'id':6,'name_zh': '喷火龙', 'name_eng': 'Charizard'},
{'id':7,'name_zh': '杰尼龟', 'name_eng': 'Squirtle'}
]
l=[]
for i in test_data:
l.append(Pokemon(i['id'],1,i['name_zh'],i['name_eng']))
for i in l:
i.show()
如果可以正常出現下圖這樣的輸出就代表已經能夠順利保存目前我們需要的寶可夢資料了。

爬蟲
接著就要開始來爬娶我們需要的資料了,可以觀察寶可夢百科的保夢列表網頁,能夠觀察到所有的寶可夢都被保存在一個很長的表格中。 我們只需要將表格中所有的資料爬下來並做一些整理就可以取得到我們需要的資料,爬取的目標跟步驟如下:

在爬蟲上我使用lxml, bs4等常見的爬蟲工具,在Colab的環境中都是無須另外下載就可以直接使用的套件,而我主要是以XPath進行元素的搜尋,用過幾次下來我認為是一個非常好用的方法。
想取得一個網站中對應元素的XPath的話可以使用Chrome DevTool(F12 or fn+F12)先在html code中找到你要找的元素,接著右鍵選Copy>>Copy XPath來複製XPath。以下是Source Code:
from lxml import html
import requests
import html as html_converter
from bs4 import BeautifulSoup
url = str("https://wiki.52poke.com/wiki/%E5%AE%9D%E5%8F%AF%E6%A2%A6%E5%88%97%E8%A1%A8%EF%BC%88%E6%8C%89%E5%85%A8%E5%9B%BD%E5%9B%BE%E9%89%B4%E7%BC%96%E5%8F%B7%EF%BC%89/%E7%AE%80%E5%8D%95%E7%89%88")
response = requests.get(url)
tree = html.fromstring(response.content)
# 使用Xpath定位到特定的table的tbody中的所有tr元素
rows = tree.xpath('//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr')
l=0
data=[]
# 在所有tr中個別進行遍歷
for row in rows:
element=[]
if l>3000:
break
row_str = html.tostring(row, pretty_print=True).decode("utf-8")
# 使用html.unescape()將HTML實體轉換回Unicode字符
unescaped_row_str = html_converter.unescape(row_str)
soup=BeautifulSoup(unescaped_row_str)
tds=soup.find_all('td')
# 讀取該tr中的所有td
for td in tds:
element.append(td.text.replace('\n',''))
l+=1
# 有一些row中不是我們要的資料 比如第一世代或是標題row 所以要檢查資料的長度是否正確
if len(element)==4:
pokemon=Pokemon(int(element[0].replace('#','')),genCheck(int(element[0].replace('#',''))),element[1],element[3])
data.append(pokemon)
for i in data:
i.show()
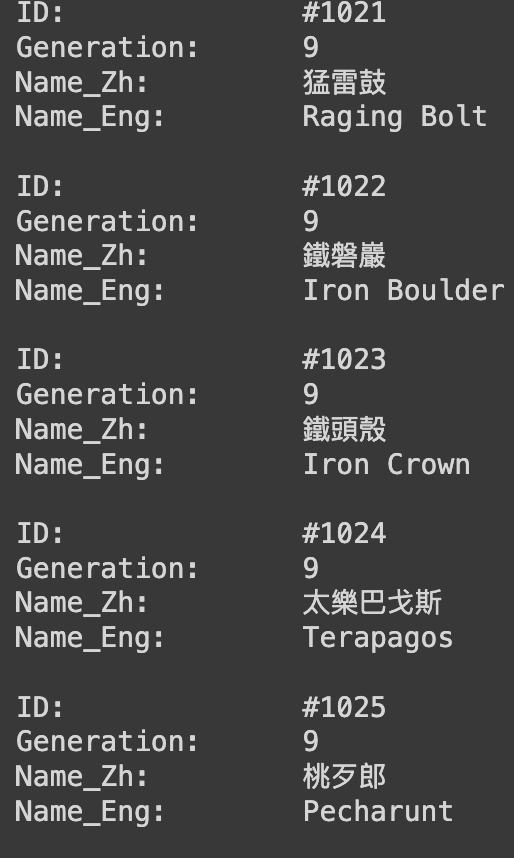
執行之後會跑一段時間,因為目前有一千出頭個寶可夢的資料需要處理,執行順利的話應該會全部印出來,但礙於Colab的規範,會因為行數過多所以前面的資料會被截到,執行正確的話會出現下圖的結果。
匯出資料
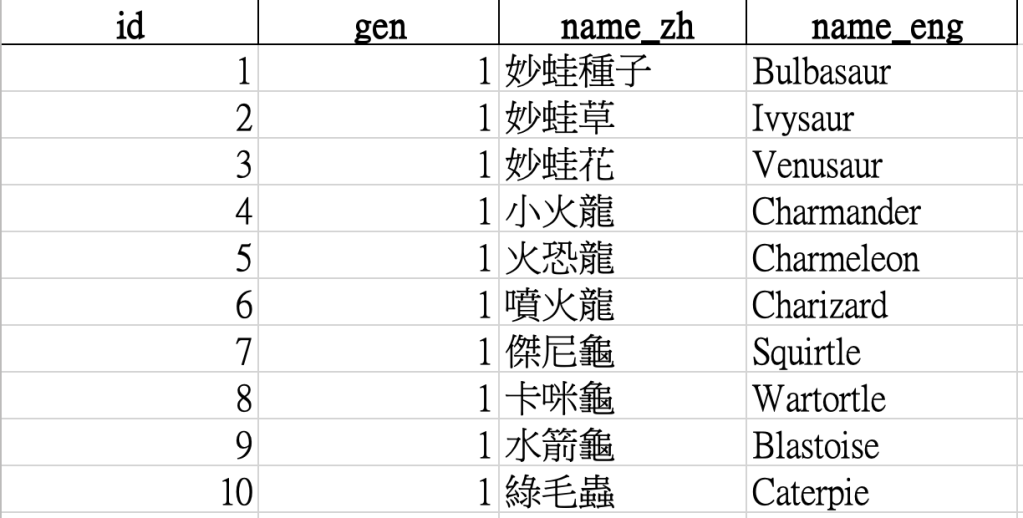
一般情況我們不會希望每次搜尋資料都要花那麼多時間在爬蟲上,所以我希望把這些爬到的資料輸出成一個Excel檔案,未來要做其他應用才會比較方便快速。 這邊搭配大家處理資料時最熟悉的Pandas來進行,Code跟從Excel截圖的成品如下:
import pandas as pd
# 將data轉換成一個字典列表,以方便轉換成DataFrame
data_dict = [{
"id": pokemon.id,
"gen": pokemon.gen,
"name_zh": pokemon.name_zh,
"name_eng": pokemon.name_eng
} for pokemon in data]
# 轉換成DataFrame
df = pd.DataFrame(data_dict)
# 將DataFrame寫入Excel文件
df.to_excel('pokemon_data.xlsx', index=False, engine='openpyxl')
結語
好啦,到目前為止已經完成了簡要的資料準備,後續我希望可以在取得所有寶可夢的種族值並進行排序,至於該如何進行每一隻寶可夢的個別資料爬取我已經想好步驟了,下篇文章再來詳細說明方法。
感謝閱讀本篇文章的每一個人,若是對我有任何建議都歡迎與我聯繫。

發表留言